24. Asynchrone Programmierung (Grundlagen)
Dieses Kapitel erklärt die Grundlagen der asynchronen Programmierung in JavaScript. Es liefert Hintergrundwissen für das nächste Kapitel über ES6 Promises.
- 24.1. Der JavaScript Call Stack
- 24.2. Die Browser Event Loop
- 24.2.1. Timer
- 24.2.2. Anzeigen von DOM-Änderungen
- 24.2.3. Run-to-completion-Semantik
- 24.2.4. Blockieren der Event Loop
- 24.2.5. Blockaden vermeiden
- 24.3. Asynchrone Ergebnisse empfangen
- 24.3.1. Asynchrone Ergebnisse über Events
- 24.3.2. Asynchrone Ergebnisse über Callbacks
- 24.3.3. Continuation-Passing Style
- 24.3.4. Code in CPS zusammensetzen
- 24.3.5. Vor- und Nachteile von Callbacks
- 24.4. Ausblick
- 24.5. Weiterführende Literatur
24.1 Der JavaScript Call Stack
Wenn eine Funktion f eine Funktion g aufruft, muss g wissen, wohin es nach Abschluss zurückkehren soll (innerhalb von f). Diese Information wird üblicherweise mit einem Stack, dem *Call Stack*, verwaltet. Sehen wir uns ein Beispiel an.
function h(z) {
// Print stack trace
console.log(new Error().stack); // (A)
}
function g(y) {
h(y + 1); // (B)
}
function f(x) {
g(x + 1); // (C)
}
f(3); // (D)
return; // (E)
Zu Beginn, wenn das obige Programm gestartet wird, ist der Call Stack leer. Nach dem Funktionsaufruf f(3) in Zeile D enthält der Stack einen Eintrag
- Ort im globalen Scope
Nach dem Funktionsaufruf g(x + 1) in Zeile C enthält der Stack zwei Einträge
- Ort in
f - Ort im globalen Scope
Nach dem Funktionsaufruf h(y + 1) in Zeile B enthält der Stack drei Einträge
- Ort in
g - Ort in
f - Ort im globalen Scope
Der in Zeile A ausgegebene Stack Trace zeigt Ihnen, wie der Call Stack aussieht
Anschließend wird jede der Funktionen beendet und jedes Mal wird der oberste Eintrag vom Stack entfernt. Nachdem die Funktion f beendet ist, sind wir zurück im globalen Scope und der Call Stack ist leer. In Zeile E kehren wir zurück und der Stack ist leer, was bedeutet, dass das Programm terminiert.
24.2 Die Browser Event Loop
Vereinfacht ausgedrückt, läuft jeder Browser-Tab (in einigen Browsern der gesamte Browser) in einem einzigen Prozess: der *Event Loop* (Offizielle Spezifikation). Diese Schleife führt browserbezogene Dinge (sogenannte *Tasks*) aus, die ihr über eine *Task Queue* zugeführt werden. Beispiele für Tasks sind
- Parsen von HTML
- Ausführen von JavaScript-Code in Skript-Elementen
- Reagieren auf Benutzereingaben (Mausklicks, Tastendrücke usw.)
- Verarbeiten des Ergebnisses einer asynchronen Netzwerkanfrage
Elemente 2-4 sind Tasks, die JavaScript-Code ausführen, über die in den Browser eingebaute Engine. Sie terminieren, wenn der Code terminiert. Dann kann der nächste Task aus der Queue ausgeführt werden. Das folgende Diagramm (inspiriert von einer Folie von Philip Roberts [1]) gibt einen Überblick, wie all diese Mechanismen miteinander verbunden sind.
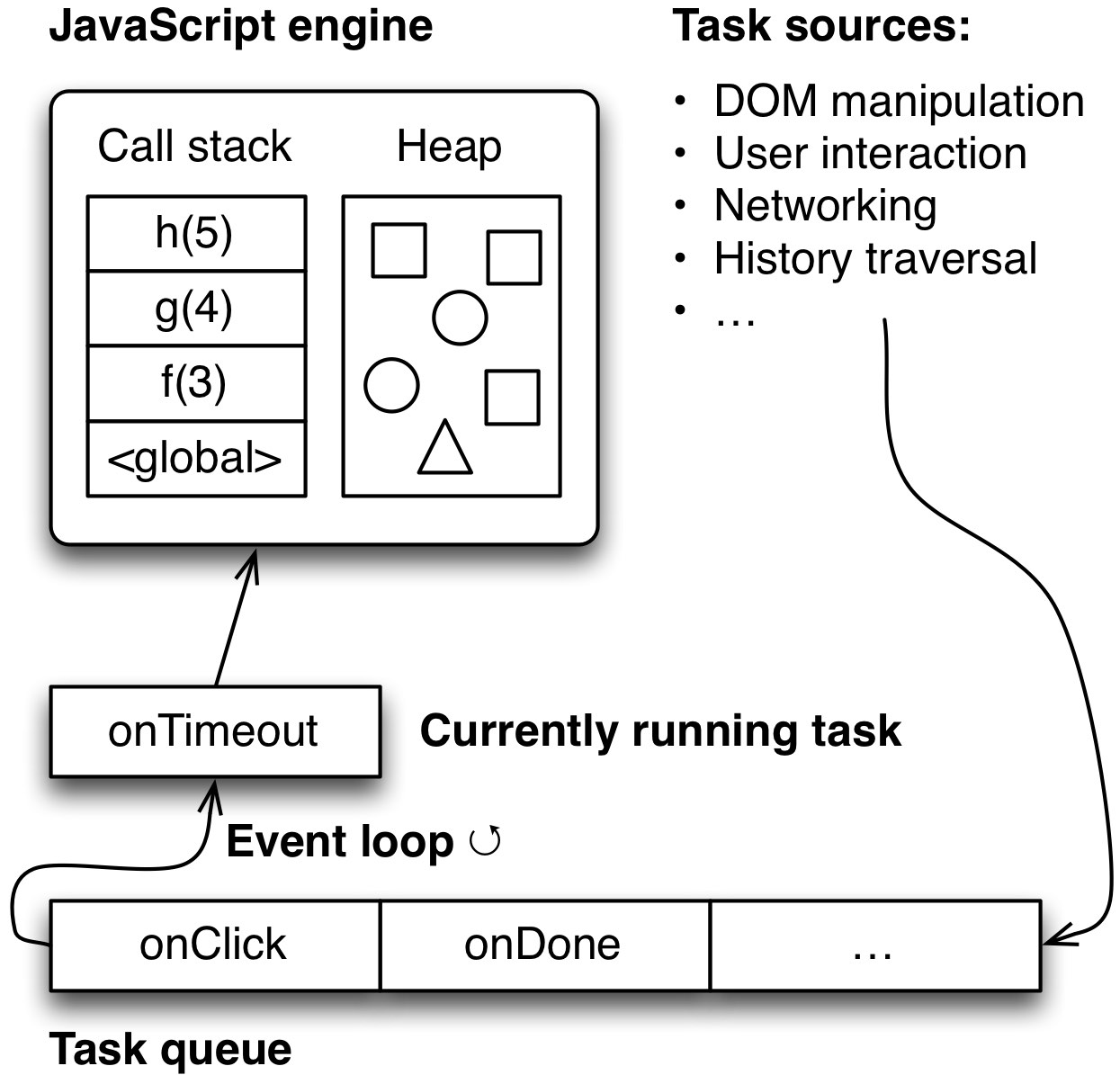
Die Event Loop ist von anderen parallel laufenden Prozessen umgeben (Timer, Eingabeverarbeitung usw.). Diese Prozesse kommunizieren mit ihr, indem sie Tasks zu ihrer Queue hinzufügen.
24.2.1 Timer
Browser haben Timer. setTimeout() erstellt einen Timer, wartet, bis er ausgelöst wird, und fügt dann einen Task zur Queue hinzu. Er hat die Signatur
setTimeout(callback, ms)
Nach ms Millisekunden wird callback zur Task Queue hinzugefügt. Es ist wichtig zu beachten, dass ms nur angibt, wann der Callback *hinzugefügt* wird, nicht wann er tatsächlich ausgeführt wird. Das kann viel später geschehen, insbesondere wenn die Event Loop blockiert ist (wie später in diesem Kapitel gezeigt wird).
setTimeout() mit ms auf Null gesetzt, ist ein häufig verwendeter Workaround, um etwas sofort zur Task Queue hinzuzufügen. Einige Browser erlauben jedoch nicht, dass ms unter einem Minimum liegt (4 ms in Firefox); sie setzen es *auf* dieses Minimum, wenn es darunter liegt.
24.2.2 Anzeigen von DOM-Änderungen
Für die meisten DOM-Änderungen (insbesondere solche, die ein Neulayout beinhalten) wird die Anzeige nicht sofort aktualisiert. „Layout occurs off a refresh tick every 16ms“ (@bz_moz) und muss über die Event Loop eine Chance zum Ausführen erhalten.
Es gibt Möglichkeiten, häufige DOM-Updates mit dem Browser zu koordinieren, um eine Kollision mit seinem Layout-Rhythmus zu vermeiden. Konsultieren Sie die Dokumentation zu requestAnimationFrame() für Details.
24.2.3 Run-to-completion-Semantik
JavaScript hat die sogenannte Run-to-completion-Semantik: Der aktuelle Task wird immer abgeschlossen, bevor der nächste Task ausgeführt wird. Das bedeutet, dass jeder Task die vollständige Kontrolle über alle aktuellen Zustände hat und sich keine Gedanken über gleichzeitige Modifikationen machen muss.
Betrachten wir ein Beispiel.
setTimeout(function () { // (A)
console.log('Second');
}, 0);
console.log('First'); // (B)
Die Funktion, die in Zeile A beginnt, wird sofort zur Task Queue hinzugefügt, aber erst ausgeführt, nachdem der aktuelle Codeblock beendet ist (insbesondere Zeile B!). Das bedeutet, dass die Ausgabe dieses Codes immer sein wird
24.2.4 Blockieren der Event Loop
Wie wir gesehen haben, wird jeder Tab (in einigen Browsern der gesamte Browser) von einem einzigen Prozess verwaltet – sowohl die Benutzeroberfläche als auch alle anderen Berechnungen. Das bedeutet, dass Sie die Benutzeroberfläche einfrieren können, indem Sie eine langlaufende Berechnung in diesem Prozess durchführen. Der folgende Code demonstriert dies.
<a id="block" href="">Block for 5 seconds</a>
<p>
<button>This is a button</button>
<div id="statusMessage"></div>
<script>
document.getElementById('block')
.addEventListener('click', onClick);
function onClick(event) {
event.preventDefault();
setStatusMessage('Blocking...');
// Call setTimeout(), so that browser has time to display
// status message
setTimeout(function () {
sleep(5000);
setStatusMessage('Done');
}, 0);
}
function setStatusMessage(msg) {
document.getElementById('statusMessage').textContent = msg;
}
function sleep(milliseconds) {
var start = Date.now();
while ((Date.now() - start) < milliseconds);
}
</script>
Immer wenn auf den Link am Anfang geklickt wird, wird die Funktion onClick() ausgelöst. Sie verwendet die – synchrone – sleep() Funktion, um die Event Loop für fünf Sekunden zu blockieren. Während dieser Sekunden funktioniert die Benutzeroberfläche nicht. Sie können zum Beispiel nicht auf den „Simple Button“ klicken.
24.2.5 Blockaden vermeiden
Sie vermeiden Blockaden der Event Loop auf zwei Arten
Erstens führen Sie keine langlaufenden Berechnungen im Hauptprozess durch, sondern verschieben sie in einen anderen Prozess. Dies kann über die Worker API erreicht werden.
Zweitens warten Sie nicht (synchron) auf die Ergebnisse einer langlaufenden Berechnung (Ihres eigenen Algorithmus in einem Worker-Prozess, einer Netzwerkanfrage usw.), sondern fahren mit der Event Loop fort und lassen die Berechnung Sie benachrichtigen, wenn sie abgeschlossen ist. Tatsächlich haben Sie in Browsern normalerweise keine Wahl und müssen die Dinge auf diese Weise tun. Zum Beispiel gibt es keine eingebaute Möglichkeit, synchron zu schlafen (wie das zuvor implementierte sleep()). Stattdessen ermöglicht setTimeout() Ihnen, asynchron zu schlafen.
Der nächste Abschnitt erklärt Techniken, um asynchron auf Ergebnisse zu warten.
24.3 Asynchrone Ergebnisse empfangen
Zwei gängige Muster zum asynchronen Empfangen von Ergebnissen sind: Events und Callbacks.
24.3.1 Asynchrone Ergebnisse über Events
Bei diesem Muster zum asynchronen Empfangen von Ergebnissen erstellen Sie für jede Anfrage ein Objekt und registrieren Ereignisbehandler damit: einen für eine erfolgreiche Berechnung, einen anderen für die Fehlerbehandlung. Der folgende Code zeigt, wie das mit der XMLHttpRequest API funktioniert
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function () {
if (req.status == 200) {
processData(req.response);
} else {
console.log('ERROR', req.statusText);
}
};
req.onerror = function () {
console.log('Network Error');
};
req.send(); // Add request to task queue
Beachten Sie, dass die letzte Zeile die Anfrage nicht tatsächlich ausführt, sondern sie zur Task Queue hinzufügt. Daher könnten Sie diese Methode auch direkt nach open() aufrufen, bevor Sie onload und onerror einrichten. Die Dinge würden aufgrund der Run-to-completion-Semantik von JavaScript genauso funktionieren.
24.3.1.1 Implizite Anfragen
Die Browser-API IndexedDB hat einen etwas eigenartigen Stil der Ereignisbehandlung
var openRequest = indexedDB.open('test', 1);
openRequest.onsuccess = function (event) {
console.log('Success!');
var db = event.target.result;
};
openRequest.onerror = function (error) {
console.log(error);
};
Sie erstellen zunächst ein Anfrageobjekt, dem Sie Ereignis-Listener hinzufügen, die über Ergebnisse benachrichtigt werden. Sie müssen die Anfrage jedoch nicht explizit in die Queue stellen, das geschieht durch open(). Sie wird ausgeführt, nachdem der aktuelle Task beendet ist. Deshalb können Sie Ereignis-Listener *nach* dem Aufruf von open() registrieren (und müssen es sogar).
Wenn Sie mit Multithreading-Programmiersprachen vertraut sind, mag dieser Stil der Anfragenbearbeitung seltsam erscheinen, als ob er anfällig für Race Conditions wäre. Aber aufgrund von Run-to-completion ist alles immer sicher.
24.3.1.2 Events funktionieren nicht gut für einzelne Ergebnisse
Dieser Stil der asynchron berechneten Ergebnisse ist in Ordnung, wenn Sie Ergebnisse mehrmals erhalten. Wenn es jedoch nur ein einzelnes Ergebnis gibt, wird die Ausführlichkeit zum Problem. Für diesen Anwendungsfall sind Callbacks populär geworden.
24.3.2 Asynchrone Ergebnisse über Callbacks
Wenn Sie asynchrone Ergebnisse über Callbacks verarbeiten, übergeben Sie Callback-Funktionen als nachfolgende Parameter an asynchrone Funktions- oder Methodenaufrufe.
Das Folgende ist ein Beispiel in Node.js. Wir lesen den Inhalt einer Textdatei über einen asynchronen Aufruf von fs.readFile()
// Node.js
fs.readFile('myfile.txt', { encoding: 'utf8' },
function (error, text) { // (A)
if (error) {
// ...
}
console.log(text);
});
Wenn readFile() erfolgreich ist, erhält der Callback in Zeile A ein Ergebnis über den Parameter text. Wenn nicht, erhält der Callback einen Fehler (oft eine Instanz von Error oder einen Unterkonstruktor) über seinen ersten Parameter.
Der gleiche Code im klassischen funktionalen Programmierstil würde so aussehen
// Functional
readFileFunctional('myfile.txt', { encoding: 'utf8' },
function (text) { // success
console.log(text);
},
function (error) { // failure
// ...
});
24.3.3 Continuation-Passing Style
Der Programmierstil der Verwendung von Callbacks (insbesondere in der zuvor gezeigten funktionalen Art) wird auch als *Continuation-Passing Style* (CPS) bezeichnet, da der nächste Schritt (die *Continuation*) explizit als Parameter übergeben wird. Dies gibt einer aufgerufenen Funktion mehr Kontrolle darüber, was als Nächstes und wann passiert.
Der folgende Code veranschaulicht CPS
console.log('A');
identity('B', function step2(result2) {
console.log(result2);
identity('C', function step3(result3) {
console.log(result3);
});
console.log('D');
});
console.log('E');
// Output: A E B D C
function identity(input, callback) {
setTimeout(function () {
callback(input);
}, 0);
}
Für jeden Schritt setzt sich der Kontrollfluss des Programms innerhalb des Callbacks fort. Dies führt zu verschachtelten Funktionen, die manchmal als *Callback-Hölle* bezeichnet werden. Sie können jedoch oft eine Verschachtelung vermeiden, da JavaScript-Funktionsdeklarationen *gehoisted* (ihre Definitionen werden am Anfang ihres Geltungsbereichs ausgewertet) sind. Das bedeutet, dass Sie vorausrufen und Funktionen aufrufen können, die später im Programm definiert sind. Der folgende Code verwendet Hoisting, um das vorherige Beispiel zu glätten.
console.log('A');
identity('B', step2);
function step2(result2) {
// The program continues here
console.log(result2);
identity('C', step3);
console.log('D');
}
function step3(result3) {
console.log(result3);
}
console.log('E');
Weitere Informationen zu CPS finden Sie in [3].
24.3.4 Code in CPS zusammensetzen
Im normalen JavaScript-Stil setzen Sie Code-Teile zusammen über
- Sie hintereinander legen. Das ist blendend offensichtlich, aber es ist gut, sich daran zu erinnern, dass das Aneinanderreihen von Code im normalen Stil eine sequentielle Komposition ist.
- Array-Methoden wie
map(),filter()undforEach() - Schleifen wie
forundwhile
Die Bibliothek Async.js bietet Kombinatoren, mit denen Sie ähnliche Dinge in CPS mit Node.js-Style-Callbacks tun können. Sie wird im folgenden Beispiel verwendet, um den Inhalt von drei Dateien zu laden, deren Namen in einem Array gespeichert sind.
var async = require('async');
var fileNames = [ 'foo.txt', 'bar.txt', 'baz.txt' ];
async.map(fileNames,
function (fileName, callback) {
fs.readFile(fileName, { encoding: 'utf8' }, callback);
},
// Process the result
function (error, textArray) {
if (error) {
console.log(error);
return;
}
console.log('TEXTS:\n' + textArray.join('\n----\n'));
});
24.3.5 Vor- und Nachteile von Callbacks
Die Verwendung von Callbacks führt zu einem radikal anderen Programmierstil, CPS. Der Hauptvorteil von CPS ist, dass seine grundlegenden Mechanismen leicht zu verstehen sind. Es gibt jedoch auch Nachteile
- Fehlerbehandlung wird komplizierter: Es gibt nun zwei Möglichkeiten, wie Fehler gemeldet werden – über Callbacks und über Exceptions. Sie müssen vorsichtig sein, beide richtig zu kombinieren.
- Weniger elegante Signaturen: In synchronen Funktionen gibt es eine klare Trennung der Belange zwischen Eingabe (Parameter) und Ausgabe (Funktionsergebnis). In asynchronen Funktionen, die Callbacks verwenden, sind diese Belange vermischt: Das Funktionsergebnis ist unwichtig und einige Parameter werden für die Eingabe verwendet, andere für die Ausgabe.
- Komposition ist komplizierter: Da das Anliegen "Ausgabe" in den Parametern auftaucht, ist es komplizierter, Code über Kombinatoren zusammenzusetzen.
Callbacks im Node.js-Stil haben drei Nachteile (im Vergleich zu denen in einem funktionalen Stil)
- Die
if-Anweisung zur Fehlerbehandlung fügt Ausführlichkeit hinzu. - Wiederverwendung von Fehlerbehandlern ist schwieriger.
- Bereitstellung eines Standard-Fehlerbehandlers ist ebenfalls schwieriger. Ein Standard-Fehlerbehandler ist nützlich, wenn Sie einen Funktionsaufruf tätigen und keinen eigenen Behandler schreiben möchten. Er könnte auch von einer Funktion verwendet werden, wenn ein Aufrufer keinen Behandler angibt.
24.4 Ausblick
Das nächste Kapitel behandelt Promises und die ES6 Promise API. Promises sind intern komplizierter als Callbacks. Im Gegenzug bringen sie mehrere wesentliche Vorteile und eliminieren die meisten der oben genannten Nachteile von Callbacks.
24.5 Weiterführende Literatur
[1] „Help, I’m stuck in an event-loop“ von Philip Roberts (Video).
[2] „Event loops“ in der HTML-Spezifikation.
[3] „Asynchronous programming and continuation-passing style in JavaScript“ von Axel Rauschmayer.